
Dieser Schadensbericht beschreibt die Technologie hinter den letzten Ausfällen in Europa und Brasilien.
Hallo, ich bin Brian „Penrif“ Bossé von der Technologieabteilung von League of Legends, und ich möchte über die Details der technischen Probleme sprechen, die Ende Februar zu Ausfällen in EUW, EUNE und BR geführt haben. Ich werde den Nerd in mir rauslassen, aber wenn du dich für die Details hinter diesen Ausfällen und die Maßnahmen, die wir zu deren Behebung ergriffen haben, interessierst, dann begleite mich doch auf dieser technischen Reise!
Die Kulisse
Als Erstes ist unserer wachsamen „Network Operations“-Zentrale aufgefallen, dass die Anzahl an neuen League-Spielen drastisch abgenommen hat.
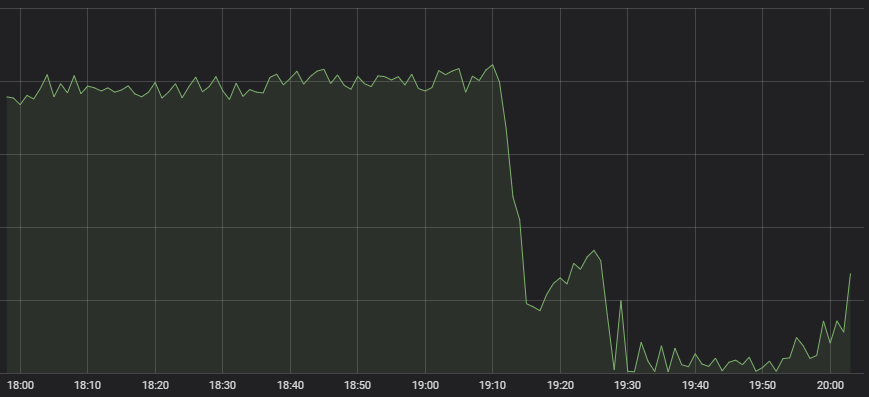
Atypisches Verhalten
An der erfolgreichen Erstellung eines Spiels sind jede Menge Systeme beteiligt (von der Gegnersuche zur Lastverteilung bis hin zum Spielserver selbst) und es ist nicht immer sofort klar, welche dieser Systeme Probleme machen. Als wir die Experten für diese Systeme zusammentrommelten und sie baten, herauszufinden, wo das Problem liegt, sagten sie uns alle, dass ihre Dienste einwandfrei funktionierten, aber nur noch wenig Traffic bei ihnen ankam. Wenn nur noch wenige Spieler ein Spiel spielen wollen, hat die Gegnersuche nicht viel zu tun.
Dieser Umstand hat also darauf hingedeutet, dass wir ein systematisches Problem hatten, das verhinderte, dass der Spieler-Traffic in unserem Backend ankam. Und die Metriken haben diese Vermutung unterstützt:
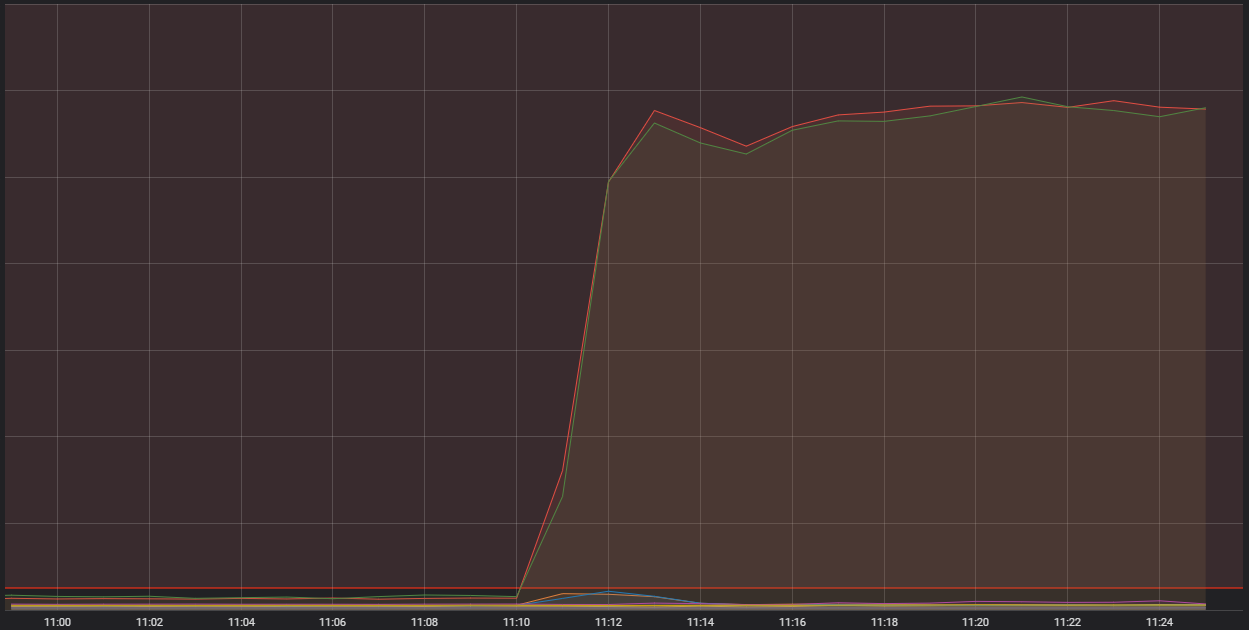
Die horizontale rote Linie ganz unten zeigt an, ab wann die Alarmglocken zu läuten beginnen
Auf dieser Grafik ist die Anzahl an eingehenden Verbindungen zu einem unserer generischen Container-Hosts zu sehen. Hierbei handelt es sich um sehr leistungsstarke einzelne Rechner, die einige kleinere Anwendungen ausführen – in der Fachsprache „Container“ genannt – die wiederum das Gesamtsystem bilden, das League ausführt. Zwei dieser Hosts hatten wesentlich mehr Verbindungen aufzuweisen, als es vertretbar gewesen wäre. Um zu verstehen, warum das passiert ist, müssen wir über eine bestimmte Container-Art sprechen, die eine „Edge“-Funktion übernimmt.
Das Leben an der Edge
Edge-Prozesse haben die Aufgabe, den Traffic vom Internet aufzunehmen, ihn zu filtern und ihn an die entsprechenden Backend-Dienste weiterzuleiten. Sie sortierten also den Müll des öffentlichen Internets aus und lassen nur schöne, saubere Byte-Ströme durch, die anschließend problemlos verarbeitet werden können. Wie du dir vielleicht vorstellen kannst, durchforsten die Edge-Prozesse jede Menge Traffic, dennoch sollte es normalerweise nicht zu derart hohen Spitzen kommen, die während dieser Ereignisse aufgetreten sind. Es gab drei Faktoren, die zusammen zu dieser Situation geführt haben – ich werde jedem dieser Faktoren einen eigenen Abschnitt widmen und sie anschließend noch einmal zusammen betrachten.
Fangen wir also an
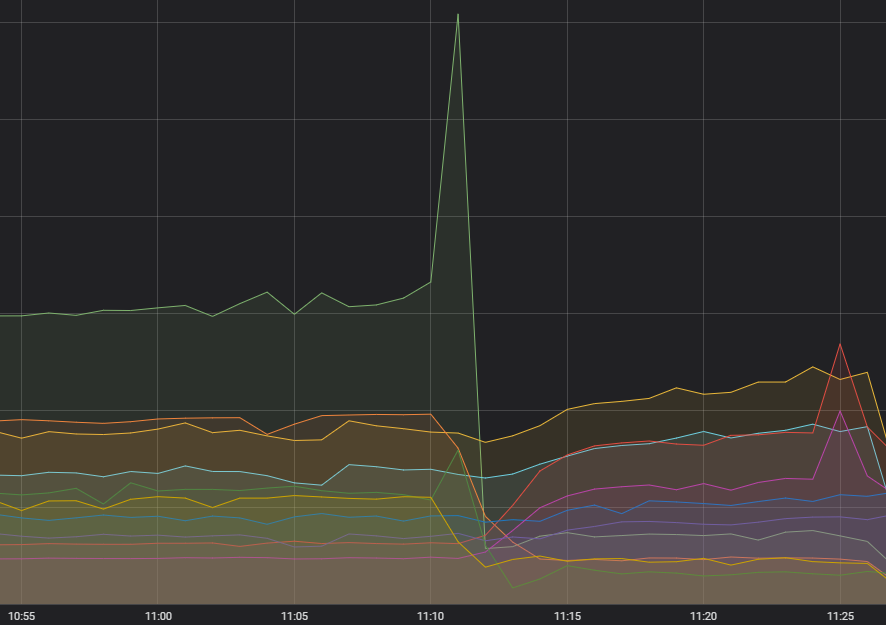
Beginnen wir mit dem Funken, der das Feuer entfacht hat – einer übertrieben hohen Zahl an Anfragen an einen Dienst. Wir konnten schon seit einigen Monaten einen Anstieg der Volatilität der Anfragen an diesen Dienst beobachten, dieser Anstieg schien jedoch keine Auswirkungen zu haben und für die Upstream-Systeme kein Problem darzustellen. Und da es keine Probleme gab, hatte dieser Anstieg für uns auch keine besonders hohe Priorität, wir behielten ihn jedoch im Hinterkopf. Mittlerweile haben wir uns jedoch eingehender damit befasst: Es gab einen Fehler bei der Ausführung der Anfragen, der dazu führte, dass sie unter gewissen Umständen immer scheiterten – und permanent erneut durchgeführt wurden.
Die Container bekamen ein Leck
Es gab ein bekanntes Problem mit der Interaktion zwischen unserem Container-System und der Version des Betriebssystems, die wir aktuell benutzen. Dabei kam es in den Eingeweiden des Betriebssystems zu Speicherlecks, die nach einer bestimmten Zeit wichtige Systemfunktionen blockierten. Vor diesem Ereignis ist das zwar noch nie passiert, dennoch hatten wir bereits 60 % des Container-Flusses von Riot mit Updates versehen. Leider war das Update der Cluster für Europa und Lateinamerika noch nicht fertig.
Glück ist wichtig
Zu guter Letzt hatten wir auch Pech. Wir nutzen eine Software, um die Container zu Gruppen zusammenzufassen, die auf einzelne Host-Rechner passen. Diese Software hat bestimmte Einschränkungen, die die Edge-Dienste, die das Netzwerk stark belasten, innerhalb einer Container-Gruppe trennen. Leider konnten wir jedoch nicht steuern, wie viele Edge-Dienste aus verschiedenen Gruppen auf demselben Computer landen, was wiederum dazu führte, dass die Edge-Dienste von EUW und EUNE auf demselben Rechner landeten. Diese Vergrößerung der Last für einen einzelnen Rechner führte schließlich dazu, dass die anderen beiden Probleme zu einem großen Zwischenfall wurden.
Bei allen Ausfällen sind Container aus mindestens drei verschiedenen Gruppen auf einem einzelnen Host-Rechner gelandet. Der Traffic der fehlerhaften Anfragen, die zusätzliche Last der Gruppen, die einen einzigen Host trafen, und der Speicherverlust des Betriebssystems führten schließlich zu einem Zusammenbruch der Gruppen und zu einem schwerwiegenden Ausfall.
Auswirkung und Lösung
Man muss in der Regel jede Menge Ressourcen aufwenden, um derartigen Problemen auf den Grund zu gehen und ihre Auslöser zu finden. Als wir entscheiden mussten, ob wir Clash starten sollten, hatten wir nicht nur einen instabilen Cluster, sondern auch den Verdacht, dass die Container bei diesen Problemen eine entscheidende Rolle spielten, wir wussten nur noch nicht, welcher Traffic betroffen war. Und obwohl Clash nicht für das Problem verantwortlich war, entschieden wir, das Turnier um eine Woche zu verschieben. Ich möchte mich aufrichtig für die Unannehmlichkeiten entschuldigen, die den Spielern durch diese Ereignisse entstanden sind, und kann dir versichern, dass wir mittlerweile alle Aspekte überarbeitet und sämtliche Probleme behoben haben.

Wir haben den Code überarbeitet, der für die fehlerhaften Anfragen verantwortlich war, und die Funktionsweise des Wiederholungsmechanismus geändert, um sicherstellen zu können, dass es in Zukunft zu keinen hohen Spitzen mehr kommen kann. Außerdem haben wir mittlerweile alle Container-Gruppen aufgewertet. Gleichzeitig arbeiten wir derzeit an Plänen, die Edge-Dienste durch ein Ausgleichssystem laufen zu lassen, um ihre Verteilung besser steuern zu können. Vorerst haben wir Alarmsysteme installiert, die das Handy eines Mitarbeiters in eine Sirene verwandeln, bis die Last manuell verteilt wurde.
Wir sind sehr zuversichtlich, dass dieses Problem in Zukunft nicht mehr auftreten wird. Dennoch möchte ich auch erwähnen, dass wir das Spiel und seine Systeme ständig weiterentwickeln und immer wieder derartige Situationen auftreten können. In solchen Fällen sind wir jedoch immer darum bemüht, den Dienst so schnell wie möglich wiederherzustellen. Danke, dass du diesen Beitrag bis zum Ende gelesen hast. Falls diese Art von Inhalt dein Interesse geweckt hat, kannst du dir in unserem Entwickler-Blog weitere Artikel über die Technologie hinter League durchlesen. Wir sehen uns jedenfalls in der Kluft.